
Please read my previous blog post about SVD(Singular Value Decomposition) if you are not familiar with.
Neural Network Structure
I have used simple feed-forwarding back-propagation neural network. Because most important part here is pre-processing step which I have applied SVD method for reducing dimension as input size of the neural network. There are two layers which has 10 neurons. Input size of network is 7 x 5 = 35 which means pixel count of character. I have used “logsig” transfer function for obtaining values between 0 and 1.
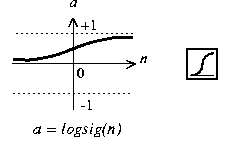
Because there are 10 output neurons in network which means 10 digit. The biggest value of these 10 output neurons is accepted as digit to be learned or recognized.
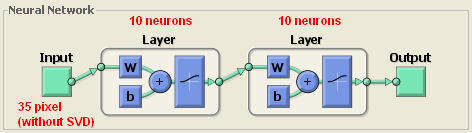
I have used “traingdx” variable of matlab for providing gradient descent backpropagation with adaptive learning rate. I have used SSE (Sum of squared error) as performance measure. Neuron weights are determined randomly. Error rate is determined as “0.1” which means training will continue until error rate reached to this value. Epoch size is determined as 50000 but training cycles never reach to this value, because the size of my training set is small. I have using 40 characters for training and 10 for test. Momentun constant which is used in back propagation is 0.95.
Using SVD(Singular Value Decomposition)
As I have mentioned on the previous parts, SVD is used to reduce dimension and uncorrelate correlated data which means feature extraction. In this project I have sampled text classification method which is mentiond in [2]. As similar to [term x document] model which is generally used in LSA (Latent Semantic Analysis), I have created [pixel x character] space. On image processing part of this project, I have cropped characters from bitmap image and stretched the size of images to 7 x 5 pixel.

For obtaining pixel X character matrix, I have convetred this image into column vector form. (35 x 1). I have 40 characters in my training set which provides 35 x 40 matrix as [pixel x character] matrix.
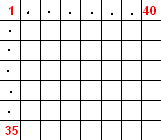
This is our A matrix which we will use in SVD part. We have added all training data into our matrix, because we will consider all possible values and its correlations for obtaining good features and suppress the noise. I have applied SVD method to this matrix and obtained 3 matrices of SVD.
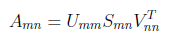
After obtaining U [35x35],S[35x40] and V[40x40] matrices, we can try to reduce dimension. There are 35 singular values in S matrix and most important ones are on the top. In U matrix columns vectors are orthonormal which means as uncorrelated as possible. We know that the vectors contain components ordered from most to least amount of variation accounted for in the original data. By deleting elements representing dimensions which do not exhibit meaningful variation, we efectively eliminate noise in the representation of pixel vectors.
Let say we have determined to use only 30 of 35 column vectors in U. In this case last 5 columns are removed. Then we will multiply all characters in training data set with this new dimension reduced U matrix.
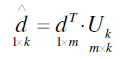
In this equation m is our original dimension value “35”, k is the reduced dimension value “30”. Transpose of d is our original character input vector exists in training data set. New d parameter is our dimension reduced input value. By making this multiplication, we are extracting most important features of character and suppress noise. Additionally we use less input values which will decrease the testing in real time applications.
For determining reduced dimension, I have used following formula which is explained in [1].
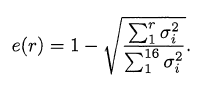
By setting an error threshold value, we can use the above equation for determining “r” value which is reduced size of singular values. In my project, I set the error threshold as “0.05”. Now the pixel vectors are shorter, and contain only the elements that account for the most significant correlations among pixels in the original dataset.
Experimental Results
I have used 3 different training and test sets in my experiments. Two handwritten data and one predefined font. All data sets contain 40 training and 10 test data. Example view of data sets are seen as below.
First data set :
Second data set :
Third data set :
We will begin with the first data set which I have created using ms paint application :)
First Data Set
I have executed my application with default parameter values, but training process taked long time and I have cancelled the process. Because all of 40 characters are the same in the training set. So, after applying SVD considering 0.05 error rate, dimension is reduced to 3 from 35. This is possible if training data is not correlated and without noise. But in this case Neural Network training process will be longer, because it is not easy to classify 10 classes with only 3 inputs. After observing this behavior, I have determined to reduce error Threshold to “0.01” for getting reduced dimension greater than 3.After this improvement, I have obtained “7” as new dimension and also input size of neural network. Results are seen in the following screen shot.
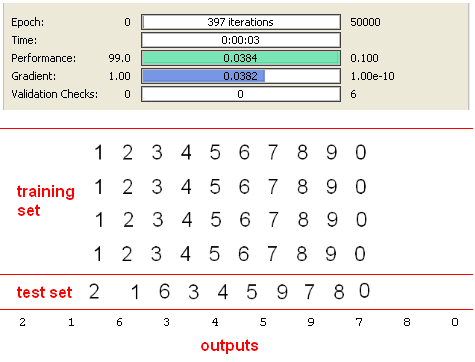
As expected, this result is very good, because training set and test set are the same. But it should be considered that this achievement is provided only using 7 inputs. On the other hand, if we execute the application without using SVD preprocessing method by applying 35 inputs the results are shown below.
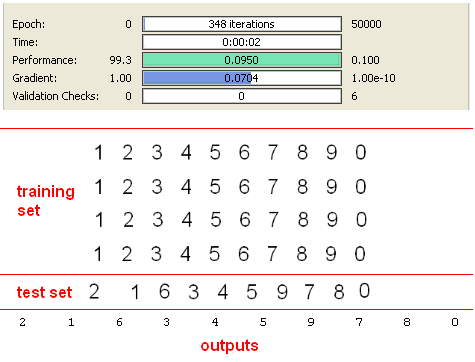
There are not so big difference between iteration counts and SVD approach really works if we consider 5 times reduced dimension of input.
Second Data Set
Second data set consists of handwritten digits created by using mouse on ms paint application. This data set is more correlated than the first one and there are some noisy pixels arround characters due to distortion while using mouse. But results with SVD are great again with using only 8 inputs instead of 35.
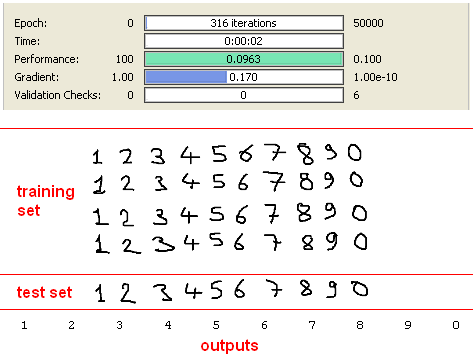
I have used same data set without SVD preprocessing step and obtained following results.
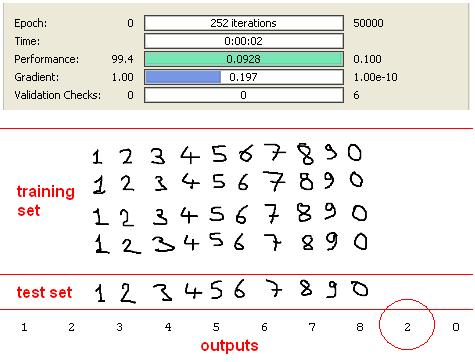
As we can see in results figure, “9” character is recognised as “2”. After this result, we can say that SVD method really suppress the noise on the original data while reducing dimension.
Third Data Set
Third data set consist of handwritten and scanned paper. Results with SVD is seen as below.
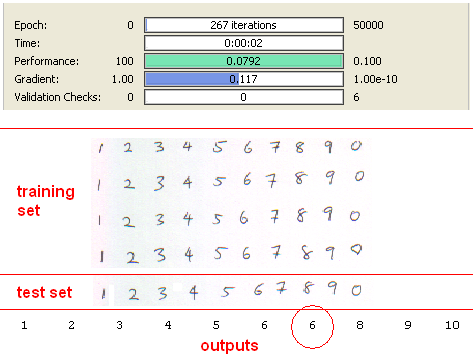
Digit “7” is recognised as “6” due to small size of training data. This problem can be prevented by using bigger training data. Anyway, %90 is a good achievement with only “8” inputs again. Without SVD results are seen as below.
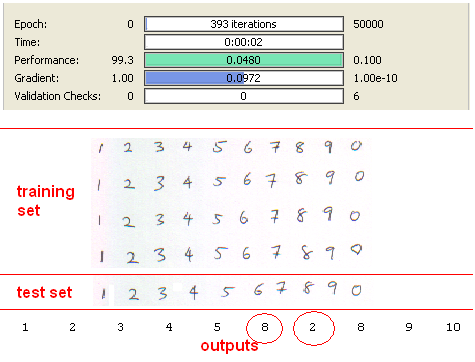
Success rate is %80 which is less than SVD preprocessing approach.
Conclusion
I have applied vector-space model commonly used in text-classification into my optical digit recognition project. According to experiments, SVD recudes the dimension drastically, suppress the noise and provide us uncorrelated data set which is easier to differentiate. So, recognizing performance of SVD is better than standart method. If the original data set has gigantic amount of dimension, SVD method can provide really good improvement for decreasing training time.
[1] “A Singular Value Decomposition: The SVD of a Matrix”, Dan Kalman, January – [1996] [2] “Neural Network for Text Classification Based on Singular Value Decomposition”, Cheng Hua Li and Soon Cheol Park, “IEEE Sevent International Conference on Computer and Informaiton Technology”, University of Aizu, Fukushima Japan, October 16 to 19, [2007]